Haltestellen reloaded
von Prof. Jens Flemming
Mal wieder ÖPNV-Haltestellen. Da gab es bereits einen Blogpost, der die Problematik von Bushalten in OpenStreetMap beleuchtet. Nun überführen wir das dort vorgestellte Demoprojekt in ein ÖPNV-Halt-Analyse-Tool mit globaler Abdeckung. Sollte doch kein so großes Problem sein...
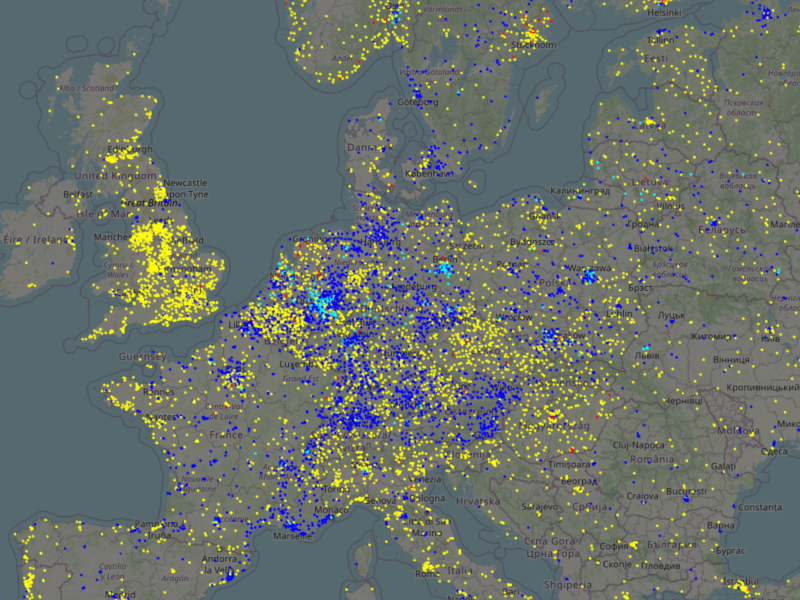 Ein Screenshot der fertigen Web-App.
Ein Screenshot der fertigen Web-App.
Bevor es losgeht, hier das Ergebnis: Public Transport Stop Analysis (PTSA).
Der grobe Plan
Zunächst ein paar Vorüberlegungen: Wir brauchen jede Menge OSM-Daten, wir müssen diese Daten verarbeiten, quasi aufbereiten, und wir wollen die aufbereiteten Daten wieder veröffentlichen, am besten in Form einer Slippy-Map, also einer interaktiv zoom- und verschiebbaren Karte wie man sie heute an so vielen Stellen im Netz findet. Das sind also die drei großen Baustellen: Daten beschaffen, Daten verarbeiten, Daten veröffentlichen.
Die OSM-Datenbank ist öffentlich zugänglich, Datenbeschaffung also eher unkritisch. Allerdings brauchen wir richtig viele Daten. Selbst wenn die öffentlichen, aus Spenden finanzierten OSM-Server unsere Anfragen hinreichend schnell beantworten würden, würden wir die OSM-Infrastruktur ganz schön belasten. Wäre vielleicht besser (und schneller!), wenn wir die OSM-Datenbank lokal vorhalten. Nach erstem groben Check der Hardware- und Software-Anforderungen sieht das machbar aus. Am Ende wird sich herausstellen, dass wir täglich ca. 2 GB OSM-Daten abfragen.
Für die Datenverarbeitung gibt es schon einen kleinen Protoyp von Algorithmus aus dem Demoprojekt, der die Aufgabe im Wesentlichen löst. Was war doch gleich die Aufgabe? Wir wollen einzelne OSM-Objekte zu Haltestellen vereinigen, die Korrektheit der in der OSM-Datenbank liegenden Daten so weit wie möglich prüfen und strukturelle Unterschiede in den Haltestellendaten finden, systematisieren und letztlich visualisieren. Man könnte auch sagen: Wir wollen den aktuellen Zustand der ÖPNV-Daten in OSM verstehen und eine Grundlage für zukünftige Verbesserungen schaffen.
Zur Visualisierung der aufbereiteten Daten müssen diese auf einem öffentlich zugänglichen Server liegen und es muss eine Web-App her, die diese Daten visualisiert. Für Datenmengen, die komplett in den Browser der Nutzer passen, geht das recht einfach. Allerdings können wir nicht Infos zu Millionen Haltestellen in einem Rutsch zum Nutzer schicken. Das würde den Browser überlasten und unseren Server ebenfalls. Da muss was besseres her, irgendwas mit dynamischem Nachladen je nach aktuell sichtbarem Kartenausschnitt.
Hardware kaufen, Software installieren
Eine grobe Schätzung des benötigten Speicherplatzes auf dem Server liefert 1 bis 2 Terabyte. Da ist erstmal Shoppen angesagt. Geld ist da, also ein paar zusätzliche SSDs für den Server kaufen. Bei der Gelegenheit kommt auch etwas Arbeitsspeicher auf den Einkaufszettel; der kann nie groß genug sein.
Die lokale Installation der OSM-Datenbank ist einigermaßen schmerzfrei. Dauert halt ein paar Stunden bis man einige 100 Gigabyte Daten in eine lokale Datenbank übertragen hat. Ein Mechanismus für den stündlichen Abgleich mit der öffentlichen OSM-Datenbank muss auch noch her. Da das so im Bündel bisher scheinbar niemand öffentlich zugänglich macht, gibt es das komplette Ich-hoste-meine-eigene-OSM-Kopie-Setup jetz als Podman-Image zum runterladen.
Die größte Herausforderung ist der Webserver zum Veröffentlichen der aufbereiteten Daten. Eine Slippy-Map besteht in jeder Zoom-Stufe aus Tausenden Einzelbildern (Kacheln oder Tiles). Diese Kacheln liegen jeweils als einzelne Dateien auf dem Server und werden nach Bedarf vom Browser des Nutzers angefordert. Eine einigermaßen vollständig abgedeckte Weltkarte, die auch bei hohen Zoom-Stufen noch vernünftig aussieht, benötigt einige hundert Millionen Kacheln. Obwohl eine einzelne Kachel kaum Speicherplatz benötigt, sind übliche Dateisysteme nicht für solche Massen an Dateien ausgelegt. Hier muss also eine Sonderlösung her, die das Kerngebiet Data Science deutlich verlässt und irgendwo zwischen technischer Informatik und Theorie der Betriebssysteme zu suchen ist. Aber sie existiert und ist inzwischen implementiert.
Die Erde ist eine Kugel
Ein wichtiger, ẃenn nicht sogar der wichtigste Punkt im Algorithmus für die Datenaufbereitung ist das Messen von Abständen zwischen Objekten wie Bahnsteigen, Haltestellenmasten, Stopppositionen von Fahrzeugen auf der Straße usw. Nun ist die Erde rund und für große Abstände kann man nicht einfach ein Lineal auf eine flache Karte legen. Jede Karte enthält nämlich Verzerrungen, da sich eine Kugel nicht ohne Verzerrungen auf eine flache Karte drücken lässt.
Eine Lösung ist, die Rundung der Erde beim Berechnen von Abständen zu berücksichtigen. Da tauchen in der Abstandsformel dann Sinuse und Cosinuse auf, was den Rechenaufwand und damit die Rechenzeit beträchtlich erhöht. Abstände in der Ebene (Karte!) berechnen geht viel schneller und einfacher. Müssen wir uns also mit der Frage beschäftigen wie groß denn die Verzerrungen in der Karte sind und ob Abstände aus der Karte für unsere Zwecke genau genug sind.
Man merkt schnell, dass übliche Weltkarten viel zu stark verzerrt sind in manchen Regionen. Bleiben lokale Karten, die nur eine kleinere Region abbilden und die Verzerrung für diese Region möglichst klein halten. Ein Stichwort hier ist die längentreue Azimutalprojektion. Je kleiner das darzustellende Gebiet, desto kleiner die Abstandfehler durch Verzerrungen. Sind also zwei Fragen zu klären:
- Wie finden wir die Projektion mit der kleinsten Verzerrung für ein gegebenes Gebiet.
- Wie klein müssen die einzelnen Gebiete sein, damit die Kartenabstände, sagen wir, bis auf plus oder minus 3 Prozent den realen Abständen entsprechen?
Für die Antworten braucht es etwas Recherche:
- Die Verzerrung ist am kleinsten, wenn wir als Kartenmitte den Mittelpunkt des kleinsten Kreises wählen, der das Gebiet umschließt.
- Der Durchmesser dieses kleinsten Kreises sollte bei höchstens 5000 km liegen.
Die Erde als Flickenteppich
Man möchte meinen, dass es irgendwo im Internet einen Datensatz gibt, der die Landmasse der Erdoberfläche entlang Ländergrenzen in einzelne Stücke teilt und dabei große Länder nochmals entlang niederwertigerer Verwaltungsgrenzen (Bundesstaaten, Bundesländer usw.) unterteilt. Warum gerade Verwaltungsgrenzen? Naja, wir brauchen eine Unterteilung in Regionen, die garantiert, dass keine ÖPNV-Halte auf der Grenze zweier Regionen liegen, da wir Abstände nur innerhalb von Regionen messen können. Da sind Verwaltungsgrenzen naheliegend. Trotz intensiver Recherche ist ein solcher Datensatz nicht aufzutreiben. Also müssen wir selbst Hand anlegen.
Bedenkt man, dass die OSM-Datenbank jede Menge Verwaltungsgrenzen enthält, sollte das ein lösbares Problem sein. Wir beginnen mit den Ländergrenzen, schauen dann welche Länder zu groß sind, unterteilen diese in Bundesstaaten, schauen wie groß diese sind, unterteilen ggf. weiter, usw. Am Ende haben wir eine Liste von Regionen, die maximal 5000 km im Durchmesser groß sind und irgendeine Form von Verwaltungseinheit repräsentieren. All diese Regionen zusammen decken die gesamte Landmasse der Erde ab.
Gesagt, getan: Nach harten Kämpfen mit der Materie gibt es nun das Tool div4aep, welches diese Idee der Unterteilung entlang Verwaltungsgrenzen umsetzt, und ein paar fertige Datensätze, die mit diesem Tool erzeugt wurden. Warum "harte Kämpfe"? Darum:
- OSM wird von Freiwilligen gepflegt. Jeder kann Daten eintragen. Das führt immer wieder zu falschen Eintragungen. So sind gelegentlich niederwertige Verwaltungsgrenzen in Entwicklungsländern falsch, die gerade frisch eingetragen wurden (z.B. keine geschlossenen Grenzlinien) oder eine Grenzlinie ist nicht verwertbar, weil das Datenformat falsch ist. Mit solchen Problemen muss jede Software, die OSM-Daten verarbeitet, rechnen und Lösungen dafür vorsehen.
- In OSM tauchen von Zeit zu Zeit seltsame Länder auf. So zum Beispiel eine "Blechinsel" vor der britischen Küste: Wikipedia zu Sealand, Sealand in OSM. Solche Dinge automatisch auszusortieren ist nicht ganz einfach.
- Man sollte annehmen, dass die Vereinigung aller Verwaltungsuntereinheiten gleich der Verwaltungseinheit ist. In Deutschland gibt es z.B. kein Stückchen Land, welches nicht zu einem Bundesland gehört. Die Vereinigung aller Bundesländer ergibt ganz Deutschland (gilt nur für die Landmasse!). In anderen Regionen der Welt sieht das aber anders aus. Da kann es "herrenlose" Teilregionen geben.
- Ganz schwierig sind Länder mit autonomen Regionen, da diese in OSM nicht gemeinsam mit den sonstigen Verwaltungseinheiten abgelegt werden (für Insider: anderes
admin_level). So gibt es beispielsweise in Griechenland eine kuriose autonome Region namens Autonome Mönchsrepublik Athos, zu der Frauen trotz EU-Mitgliedschaft der Region keinen Zutritt haben. Sowas findet man nur, wenn man Data Science studiert ;-). - Die Antarktis ist in OSM nur schwierig darstellbar, da am Kartenrand gelegen und alle Längengrade umfassend. Da dort eher keine (relevanten) ÖPNV-Halte zu vermuten sind, wird die Antarktis nicht weiter berücksichtigt.
- In einigen entlegenen Gebieten sind die kleinsten Verwaltungseinheiten größer als die gesetzte Grenze von 5000 km. Eine weitere Teilung ist nicht möglich.
Karten mit minimaler Verzerrung
Bleibt noch das Problem zu klären, wo der Mittelpunkt der Karte für jede Region liegen muss, damit die Verzerrung bei der längentreuen Azimutalprojektion minimal ist. Wir erinnern uns: Dazu benötigen wir den Mittelpunkt des kleinsten Kreises, der die Region enthält.
Die Randlinie einer Region kann man sich als große Menge von Punkten vorstellen, die durch gerade Linien verbunden sind. So sind Grenzen in OSM abgelegt. Wie findet man nun den kleinsten Kreis, der eine gegebene Punktwolke umschließt? Für Punktwolken in der Ebene gibt es den Welzl-Algorithmus. Wir brauchen aber einen Algorithmus, der auf einer Kugeloberfläche kleinste umschließende Kreise bestimmt. Schließlich haben wir ja noch gar keine "flache" Darstellung unserer Region; die wollen wir doch gerade mittels einer geeigneten Projektion finden!
Das Problem des kleinsten umschließenden Kreises taucht in vielen Anwendungsgebieten auf. So zum Beispiel auch im Operations-Research (Planung von verteilten Produktionsnetzen, Warentransport usw.). Entsprechend viel Literatur gibt es und da sind auch Lösungen für Kugeloberflächen dabei. Aber alle sind irgendwie unbefriedigend. Die einen können nur mit Halbkugeln umgehen, die anderen sind sehr langsam. Wir müssen pro Region einige 10000, teils auch einige 100000 Punkte verarbeiten. Da muss ein schneller Algorithmus her.
Nutzt alles nichts. Wir müssen wiedermal selber nachdenken und einen Algorithmus bauen. Kann ja nicht so schwer sein, den Welzl-Algorithmus auf Kugeloberflächen zu übertragen. Stellt sich raus: Ist auch nicht so schwer, hat aber diverse kleinere Fallstricke bei der praktischen Umsetzung. Die Details und eine Lösung gibt es in A simple linear time algorithm for smallest enclosing circles on the (hemi)sphere. So ist aus ein bisschen Haltestellenanalyse gleich noch eine wissenschaftliche Veröffentlichung zu einem über Jahrzehnte nur unbefriedigend gelösten Problem entstanden.
Die praktische Umsetzung als Python-Bibliothek hört auf den Name secots.
Launch
Alles zusammengebaut, getestet, auf den Server geschoben und schon läuft die Sache ("schon" = mehrere Monate). Ein paar kleine Zipperlein tauchen in den ersten Betriebswochen noch auf, lassen sich aber mit vertretbarer Mühe beseitigen. Die ersten Nutzer haben gleich ein paar Vorschläge zur Verbesserung der Bedienelemente in der Web-App. Die werden noch spontan eingebaut.
Dann kommt der Lohn für die Mühen: Feedback aus allen Teilen der Welt. Beispielsweise hat ein Nutzer aus Los Angeles mit PTSA (so heißt das Projekt in Kurzform) Fehler in den OSM-Daten zum örtlichen U-Bahn-Netz gefunden und beseitigt. Aus den Niederlanden kommt eine Rückmeldung, die letztlich eine größere Diskussion in der niederländischen OSM-Community auslöst. Dort wurden über Jahre von einer Hand voll Mappern Bushalte sehr seltsam (man könnte auch sagen: falsch) gemappt.
Genau das war das Ziel von PTSA: Fehler in den OSM-Daten finden und visualisieren, damit sie beseitigt werden können.
Mission accomplished.