Warum das alles nicht sooo einfach ist...
von Prof. Jens Flemming
Den ÖPNV im Zwickauer Umland analysieren und Fahrzeiten visualisieren? Kein Problem? Eigentlich nicht, aber irgendwie doch. Ein Blick in den bunten Alltag eines Data-Scientist.
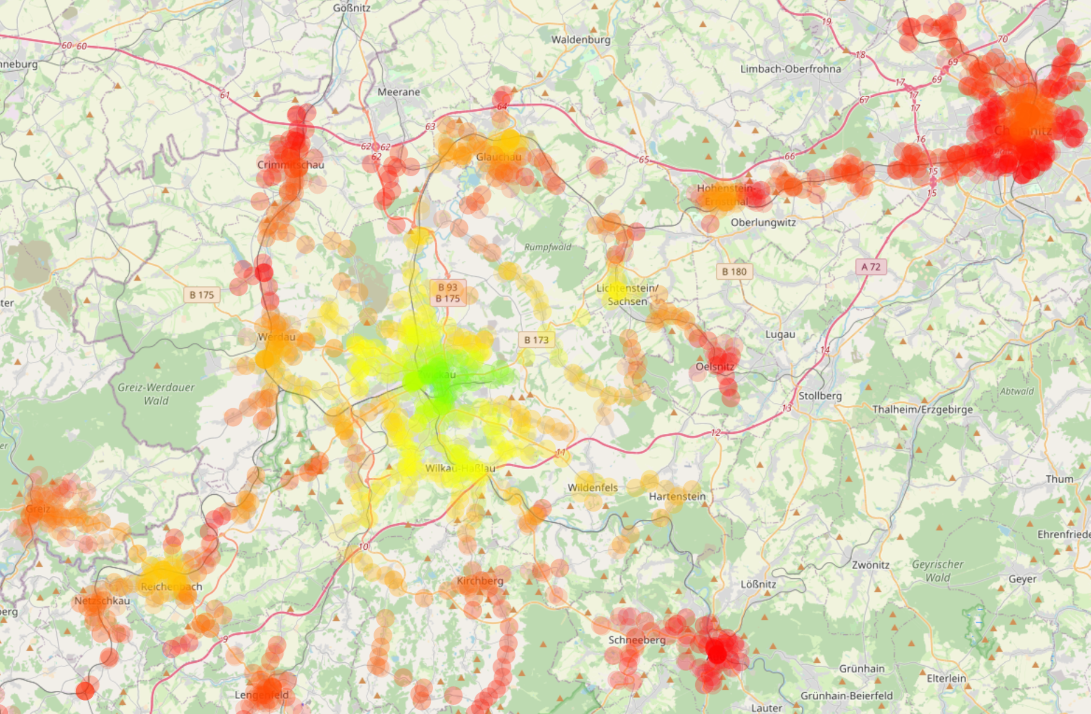 Karte vom Zwickauer Umland mit den Abfahrtszeiten nach Zwickau (rot sehr früh, gelb früh, grün kurz vor 7:30 Uhr)
Karte vom Zwickauer Umland mit den Abfahrtszeiten nach Zwickau (rot sehr früh, gelb früh, grün kurz vor 7:30 Uhr)
Die Ergebnisse:
- interaktive Karte mit Abfahrtszeiten für eine Ankunft am Montag 9:15 Uhr
- interaktive Karte mit Abfahrtszeiten für eine Ankunft am Dienstag 7:25 Uhr
Vorgeschichte
Neues Semester, neue Studierende, neue Überraschungen. Zum Start des Wintersemesters sah sich Prof. Flemming vom Fachbereich Mathematik und Data Science mit einem bisher nicht weiter beachteten Problem konfrontiert: Ein Studierender der Veranstaltung "Data Science I" meinte, er könne nicht 7:30 Uhr zur Vorlesung in Zwickau sein, da keine passende ÖPNV-Verbindung existiere.
In der Tat: Obwohl er nur 20 Kilometer Luftlinie von der Hochschule entfernt wohnt, ist Zwickau für ihn vor 7:50 Uhr mit dem ÖPNV nicht erreichbar. Einzelfall oder "Systemversagen"? Da hilft nur eine umfassende Analyse des ÖPNV-Netzes im Zwickauer Umland.
Der Plan
Aktuelle und vollständige Fahrplandaten gibt es frei im Internet, z.B. unter gtfs.de. Verbindungen mit Fußwegen sollten auch kein Problem sein; wir haben ja das außerordentlich nützliche OpenStreetMap. Fehlt noch ein bisschen Software zum Verarbeiten der ganzen Daten und zum Analysieren vollständiger ÖPNV-Verbindungen mit Umsteigen und kleineren Fußwegen (Fachbegriff: Routing). Gibt es alles in der wundervollen Open-Source-Welt.
Ergebnisse auf Kartendaten visualisieren ist Teil des zweiten Semesters im Studiengang Data Science und ist mit den heute verfügbaren Tools schnell gemacht.
Das Ganze sieht aus wie ein kleines Abendprojekt von zwei, vielleicht drei Stunden. Also nicht aufschieben, sondern loslegen!
Die Sache mit den Daten
Für Fahrplandaten wird heute meist das offene Format GTFS benutzt. Für Deutschland liegen alle Fahrplandaten kostenfrei im Internet zum Download bereit: gtfs.de. Da ist vom Fernverkehr bis zum Dorfbus alles drin; sind keine 200 Megabyte, also sehr entspannt in der Handhabung.
Gehzeiten zwischen benachbarten Haltestellen können aus OpenStreetMap (OSM) extrahiert werden. Da wird es schon spannender: Wie bekommen wir die OSM-Daten des Zwickauer Umlands auf den eigenen Computer?
- Variante 1: Wir nutzen die Exportfunktion der OSM-Website. Scheitert leider mit einer Fehlermeldung, da die gewählte Region, und damit die Datenmasse, zu groß ist. Das würde die Server hinter der OSM-Website zu sehr belasten.
- Variante 2: Wir laden die komplette Welt runter, die sogenannte Planet-Datei. Die hat eine Größe von über 60 Gigabyte; vielleicht ein bisschen "heavy". Wir brauchen nur das Zwickauer Umland.
- Variante 3: Wir schauen, ob nicht irgendwo OSM-Daten einzelner Kontinente oder Länder zu haben sind. Siehe da: Geofabrik bietet kostenlos entsprechende Zusammenstellungen an. Wir lassen uns nicht lumpen und nehmen gleich mal Europa. Zwickau ist nicht weit von Tschechien, also sind auch ÖPNV-Verbindungen aus dem tschechischen Grenzgebiet interessant.
Apropos Tschechien: Ein paar GTFS-Daten für Tschechien wäre noch von Interesse. Leider Fehlanzeige. Scheinbar bieten nur die Prager Verkehrsbetriebe ihre Fahrpläne im GTFS-Format an. Die tschechische Staatsbahn jedoch nicht. Somit wird es leider keine Verbindungsanalyse im Grenzgebiet geben. So gern auf die schleppende Digitalisierung in Deutschland geschimpft wird; bei Open-Daten ist Deutschland weiter als manches Nachbarland.
Zu viele Daten
Hat man alle Daten beisammen, heißt es: Unnötiges entsorgen. Das ist ein wichtiger Schritt bei Big-Data-Projekten um den Verarbeitungsaufwand in Grenzen zu halten.
Aus den Fahrplandaten nur die der interessanten Region zu extrahieren ist kein Problem. Standardformat, Standard-Software, fertig. Oh, kleines Problem: Die verwendete Software (siehe unten) konvertiert die GTFS-Daten in ein anderes Format bei der Verarbeitung. Aus den paar hundert Megabyte sind nun fast 40 Gigabyte geworden! Naja, macht nichts. Ist genug Speicherplatz verfügbar.
Nun zur OSM-Europa-Karte. Gleiches Spiel wie bei den Fahrplandaten: Standardformat, Standard-Software, fertig. Rechenzeit? Exorbitant! Arbeitsspeicherbedarf? Ebenfalls Exorbitant! Der heimische Laptop gibt auf (früher: "out of memory", heute etwas subtiler). Weiter geht es auf einem der Hochleistungsrechner an der Hochschule. Die 192 Gibabyte Arbeitsspeicher reichen zum Glück. Rechenzeit ist nahezu egal; über Nacht ist es fertig geworden.
Die Software-Frage
Damit das Projekt Eingang in die Lehrveranstaltungen zum Data-Science finden kann, soll alles in Python implementiert werden. Also muss ein Python-Package her, welches einerseits GTFS-Daten verarbeiten kann, andererseits ÖPNV-Verbindungen routen kann, optimalerweise gleich mit Fußweganteilen.
Im Open-Source-Universum gibt es unendliche Menge GTFS-tauglicher Software, aber nur wenige Projekte, die routen können und die ein einigermaßen einfaches Interface anbieten. Die Wahl fällt auf gtfspy, welches 2017 für ein Forschungsprojekt an einer anderen Hochschule entwickelt wurde.
Erste Tests zeigen schnell: Das wird ein harter Kampf. Mangels besserer Alternativen müssen wir ihn allerdings aufnehmen.
Die Installation hakt, da sich seit vier Jahren niemand mehr um das Projekt gekümmert hat. Die Abhängigkeiten zu anderen Python-Packages sind veraltet. Schlimmer noch: Ein Teil der für die Installation benötigten Packages ist selbst veraltet. Ein Fass ohne Boden.
Hier kommt "Open Source" ins Spiel. Das gtfspy-Package ist komplett in Python geschrieben. Wir können also alles selbst reparieren: Abhängigkeiten aktualisieren und veralteten Code korrigieren. Letztlich läuft die Sache dann zufrieden stellend. Die ursprünglich geplanten zwei bis drei Stunden für das Projekt sind laaaange um und es ist noch nicht wirklich losgegangen...
Jetzt geht's los
Jetzt, wo alles läuft, noch ein paar Zeilen Quellcode getippt, schon blubbern die Fahrzeiten von allen Haltestellen der Region nach Zwickau über den Bildschirm. Das Routing läuft erstaunlich schnell; die Reparaturen an gtfspy haben sich also gelohnt. Immerhin werden Zehntausende von Verbindungen innerhalb weniger Minuten generiert.
Bleibt noch die Visualisierung. Kurz überlegen wie das Ergebnis aussehen soll, die sonst für ähnliche Zwecke verwendeten, gut verstandenen Python-Packages nutzen, fertig. Fertig? Wo kämen wir denn hin? Die üblichen Tools versagen den Dienst. Ein verfügbar geglaubtes Feature (Kreise auf interaktive Karte malen) ist (noch?) nicht implementiert!
Visualisierung
Zur Visualisierung bedarf es also zunächst einer Analyse, welche Python-Packages die gewünschte Funktionalität liefern. Das ist mit viel Lesen und Ausprobieren verbunden. Das Projekt ist jetzt bei 20 statt 2 Stunden, mindestens. Letztlich fällt die Wahl auf folium und die Sache läuft.
Erste schicke Bilder sind da. Aber hier müsste noch was anders werden. Dort sieht es noch nicht so schick aus. Viele kleine Anpassungen sind nötig.
Die interaktive Karte reagiert recht träge. Also verschiedene Visualisierungstechniken (Rastergrafiken, Vektorgrafiken, Scatter-Plots,...) ausprobieren. Vielleicht die Technik je nach Zoom-Level anpassen? Bis Zufriedenheit einkehrt, vergehen noch etliche Stunden.
In der Nahansicht werden nun alle Haltstellen durch einen Marker gekennzeichnet und beim Überfahren mit der Maus erscheint die Abfahrtszeit. Ach du Schreck! Da sind ja Massen von Haltestellen! Hä? So viele Haltestellen und so dicht? Ein Blick in die Daten zeigt: Größere Haltestellen, wie beispielsweise Bahnhöfe, tauchen in den GTFS-Daten mehrfach auf, mit leicht unterschiedlichen Geokoordinaten. Ein genauerer Blick zeigt: Bei Bahnhöfen wird jeder Bahnsteig als eigene Haltestelle geführt. Das ist für das Routing sicher sinnvoll, für die Visualisierung definitiv nicht. Wer will schon 20-mal "Chemnitz Hbf" auf der Karte sehen?
Post-Processing
Das Zu-Viele-Haltestellen-Problem ruft nach einem recht komplexen Post-Processing. Zusammengehörige Haltestellen (z.B. Bahnsteige eines Bahnhofs) wollen gruppiert werden und in jeder Gruppe ist die beste Fahrzeit zu ermitteln. Rechenzeit und Arbeitszeit gehen ins Land... immerhin keine größeren Probleme bei diesem Schritt.
Merke: Den größten Aufwand bei Data-Science-Projekten macht das Pre-Processing (Daten suchen, reinigen, umstrukturieren), den zweitgrößten das Post-Processing (die rohen Ergebnisse in vorzeigbare Form bringen). Das bisschen "Processing" dazwischen ist schon fast ein Witz dagegen.
Fast fertig
Zum Schluss noch etwas Politur. Auf die interaktive Karte müssen noch Hinweise zur Datenquelle und deren Lizenzierung, zum Autor, und zum Kartenverständnis (Farbskala, etwas Text). Aber wie? Das folium-Package erzeugt eine HTML-Datei (Webseite), die jede Menge JavaScript enthält. Die könnte man nachträglich um die gewünschten Elemente ergänzen. Wenn man HTML und JavaScript versteht... Ein Data-Scientist muss auf vielen Gebieten fit sein.
Angenehmer und pflegeleichter als in der HTML-Datei rumzubasteln wäre es, wenn man die Zusatzelemente gleich aus dem Python-Code heraus generieren kann. Also mal wieder eine Stunde oder auch zwei Stunden Recherche, noch ein paar "hacky" Selbstbaulösungen, und das Projekt ist fertig. Naja, fast: Noch auf den Webserver schieben, vorher in verschiedenen Browsern testen, die Ansicht auf Mobilgeräten checken, Barrierefreiheit?,...
Lust bekommen? ;-)
Das Projekt ist Teil der Veranstaltungen "Data Science I" und "Data Science II" bei Prof. Flemming. Das ausführliche Vorlesungsskript ist öffentlich zugänglich: Data Science and Artificial Intelligence for Undergraduates.